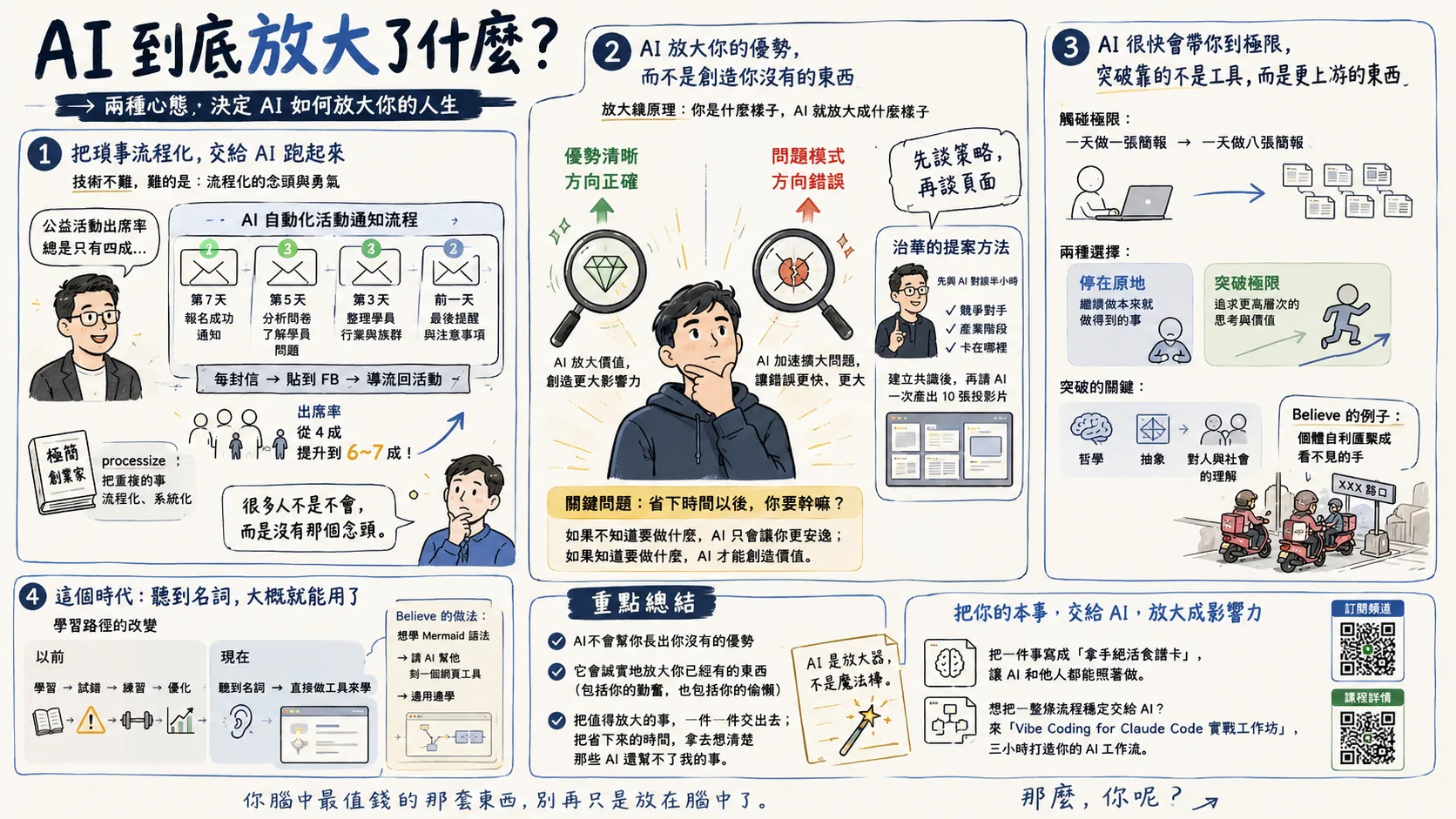
YouTube の逐語録はいつも汚くて繰り返しばかりですか?私は午前中、ビデオノートと呼ばれるクリーンなオープンソースガジェットを作成しました
*▲ 毎日使っているガジェットには、身近なトラブルが隠れていることがよくあります。 *
YouTube で技術的なスピーチやインタビューをよく見ます。それらを見た後、逐語的に記録を残し、その後の執筆や検索を容易にするためにいくつかの重要なポイントに整理したいと思います。 実は、私は以前にAIツールを使って講義内容を素早く要約・整理する方法について書きました。しかし、今回はさらに一歩進んで、ソースから逐語的な原稿をクリーンアップしたいと思います。 市場にはそのようなツールがたくさんありますが、それらをラウンドで使用した後、それらには共通の問題があることがわかりました。 それは、吐き出される逐語的なテキストがあまりきれいではないということです。そこで私は午前中をかけて、video-notes という名前の更新版を自分で作成し、オープンソース化しました。
この記事は 2 つの部分に分かれており、前半は開発プロセス中に書き留めておく価値があると思われるいくつかの判断事項を、後半はチュートリアルとして使用してください。 ソース コードはここにあります: github.com/iamvista/video-notes。
それは何をするのですか
簡単に言うと、YouTube リンクまたはローカル ビデオ ファイルを指定すると、Markdown のコピーが 2 つ作成されます。1 つはタイムスタンプ付きの完全な逐語的なドラフトで、もう 1 つは整理された重要なメモ (TL;DR、トピックごとのキー ポイント、クリックしてジャンプできる章を含む) です。
簡単に言うと、クロード コード のスキルです (プログラミングができなくても問題ありません。以前に クロード コードを使用するためのライターのための完全な独習ガイド) という記事を書きました)。より特殊な設計は分業です。 Python スクリプトは、逐語的なドラフトをクリーンアップすることのみを担当します。判断が必要な重要なポイント、要約、章は、逐語的に草案を読んだ後、AI に書かせます。 この方法で書かれたメモは、API 呼び出しの強制的なリストではなく、人間によって書かれたもののように見えます。
開発経験
1. 依存性ゼロは偏執的ですが、それだけの価値はあります
ツール全体は 7 つの Python スクリプトで構成されており、それらはすべて標準ライブラリのみを使用し、pip パッケージはありません。 必要なシステム ツールは yt-dlp、ffmpeg、curl の 3 つだけです。これらはすでに開発マシンに常駐しています。
なぜそんなに執拗ですか? なぜなら、この種のガジェットで最も怖いのは、半年後に戻って使用すると、パッケージのバージョンが競合したり、仮想環境が壊れたり、メンテナンスのために特定の依存関係が停止したりすることになるからです。 依存層が 1 つ減るということは、将来壊れるものが 1 つ減るということです。 Whisper API を呼び出す場合でも、openai パッケージをインストールする代わりに、curl を直接使用します。 この偏執症により、環境の変化による誤動作はほとんど不可能になります。
2. YouTube の自動字幕の繰り返しがこのツールの本当の難しさです。
YouTube の自動字幕を取得したことがある場合は、すべての単語が時折繰り返されることに気づくでしょう。 その理由は、自動字幕では 2 行のスクロール ウィンドウ形式が使用されているためです。つまり、前の文の末尾が次の文の先頭と重ねられ、隣接する字幕ブロックに単語が 2 ~ 3 回表示されます。 それを直接まとめると、逐語的な原稿全体がどもる幽霊のように読めます。
類似ツールの多くはここで問題が発生します。 私がこれに対処する方法は、2 つの重複のそれぞれについて戦略を書くことです。 1 つは、字幕の次のブロックが前のブロック (成長タイプ) を完全に含み、それを長いブロックに置き換えることです。もう 1 つはスライディング ウィンドウの部分的なオーバーラップです。前のブロックの終わりと次のブロックの始まりで最大の繰り返しセグメントを比較し、真に新しい単語だけを残します。 処理後は、口ごもらずに原稿を最後まで読みましょう。
 *▲ YouTube のスクロール字幕から繰り返しの単語を削除して、逐語的に読めるようにします。 複製ロジックのこのセクションは、このツールの中で最も労力がかかり、価値のある部分です。 *
*▲ YouTube のスクロール字幕から繰り返しの単語を削除して、逐語的に読めるようにします。 複製ロジックのこのセクションは、このツールの中で最も労力がかかり、価値のある部分です。 *
このロジックはプロジェクト全体で最も労力を費やしており、これが他のロジックよりもクリーンだと私が考える理由の鍵でもあります。
3. 機械翻訳された字幕は必要ありませんが、オリジナルのテキストは必要です
自動字幕付きの YouTube 動画には、実際には約 150 個の自動翻訳された字幕トラックが含まれています。 多くのツールは非常に便利です。中国語が必要な場合は、携帯電話を手に取り、中国語の字幕を読むことができます。 ただし、機械翻訳された字幕の品質は、元の言語での認識結果よりもはるかに低くなります。
そこで私は意図的にオリジナルのトラックのみをキャプチャしました。最初に手動字幕を探し、次にオリジナル言語の手動字幕を探し、最後にオリジナル言語の自動字幕に戻ります。 翻訳はAIが要約をまとめるまで放置されます。このステップでの理解は、逐語的な機械翻訳よりもはるかに優れています。 曲がった中国語版よりも、英語で正確な逐語的な草稿を入手する方が良いでしょう。
4. 字幕が優先され、ウィスパーは単なるバックアップです
可能であれば字幕を使用してください。これが最も早くて安価な方法です。 ビデオに利用可能な字幕がない場合 (ローカル ビデオ ファイル、または字幕がオフになっているビデオなど) にのみ、Whisper が使用されます。低ビット レートのモノラル オーディオを抽出し、ファイル サイズに従って API 制限を超えない小さなセグメントに分割し、各セグメントを文字起こしして、タイムスタンプを追加し直します。
このため、OPENAI_API_KEYが選択されます。ほとんどの場合、まったく使用されません。 これは、本当に音声メッセージを文字に起こしたい場合にのみ必要です。 最初からブロックするのではなく、実際に必要になる瞬間までこのチェックを延期します。
5. オープンであることは、利己主義を打ち破る訓練です
私自身が使用しているバージョンでは、出力は Obsidian ナレッジ ベースに直接書き込まれ、パスとフィールドの形式は個人のワークフロー用にハードコーディングされています。 オープンソース化するには、まずこれらのものを解体する必要があります。
すべてのハードコーディングされたパスを共通の —out-dir パラメータに置き換えました。 デフォルトの出力は現在のディレクトリです。 もともとナレッジ ベースにバインドされていた関数は、出力を独自のメモ作成システムに接続する方法を示すファイル内のサンプルとして書き直されました。 バックボーンは普遍的なままであり、宛先はユーザーの決定に委ねられます。実際、この解体作業を通して、道具の本質とは何か、自分の癖とは何かについて、はっきりと考えさせられました。
使用方法のチュートリアル
プレインストール
まず、3 つのシステム ツールをインストールします (macOS を例にします)。
「」バッシュ 醸造インストールyt-dlp ffmpeg 「」
Python には 3.9 以降のみが必要で、何も pip インストールする必要はありません。
スキルを Claude Code のスキル ディレクトリにコピーします。
「」バッシュ git clone https://github.com/iamvista/video-notes ~/.claude/skills/video-notes 「」
基本的な使い方
クロード コードで直接呼び出します。
「」 /video-notes https://youtu.be/<ビデオ ID> 「」
ローカルビデオファイルを処理し、出力ディレクトリと言語を指定します。
「」 /video-notes ./talk.mp4 —out-dir ./notes —lang zh 「」
実行後、キーノートと完全な逐語的なドラフトという 2 つのファイルが得られます。 YouTube ソースからのチャプターのタイムスタンプは、クリック可能なジャンプ リンクになります。
AI に依存せず、コマンド ライン ツールとして直接使用します
きれいなそのままのドラフトだけが必要で、後でそれを整理する方法を決定する場合は、基礎となる CLI を直接実行できます。 これは、transcript.json のコピーを吐き出します。
「」バッシュ
python3 scripts/cli.py “https://youtu.be/
JSON には、ビデオ情報 (タイトル、チャンネル、長さ)、逐語的なソースが字幕かウィスパーか、各セグメントの開始秒数とテキストが含まれています。他のプロセスにフィードするために使用することも非常に便利です。
字幕のないビデオをどうするか
ビデオに利用可能な字幕がない場合、ツールは Whisper を使用して自動的に文字起こしします。 現時点では、最初にキーを設定する必要があります。
「」バッシュ エクスポート OPENAI_API_KEY=sk-… 「」
字幕付きのビデオの場合、この手順はまったく必要ありません。
独自のナレッジベースを受け取る
—out-dir はカスタム シームです。 それをノート ライブラリの受信箱にポイントし、SKILL.md の手順 5 の指示に従ってノートのフロントマター フィールドを使い慣れた形式に調整すると、各ビデオのノートがシステムに自動的にアーカイブされます。 逐語的なパイプラインは汎用的なままであり、どのように見えるかはあなた次第です。
ちょっとした反省
このツールは、アイデアから約 1 日でオープンソースになりました。 私にとって、それは 1 つのことを裏付けています。あなたが何を望んでいるのかを正確に知っていて、詳細を正しく理解する意欲がある場合 (重複除外ロジックの部分など)、Vibe コーディングは速いだけでなく、既製のツールよりもニーズを満たすものを生成できるということです。 これは、私が以前に述べたこと、AI 活用の出発点はツールを選ぶことではなく、ワークフローを解体することである と重なります。
**video-notes は、午前中にバイブコーディングによって作成された小さなツールです。 ** アイデアを日常言語で説明する方法を学び、その日のうちに AI によって Web サイトを使用したオンライン作品に変換できるようにしたい場合は、私の Vibe コーディング実践ワークショップ へようこそ。基礎ゼロ、エンジニアリングの背景は不要で、3 時間で本当に自分のものとなる作品を持ち帰ることができます。

正直に言うと、このツールは建築においては大したものではありませんが、私は毎日使用しています。 AI によってツールの敷居が低くなったとき、本当に価値があるのはあなたの判断力とセンスです: 逐語的に書かれた原稿が実際に汚いことに気づいたことがありますか、そしてそれをきれいにするのに午前中を費やすつもりはありますか?ビデオの逐語的トランスクリプトのノイズに頻繁に悩まされている場合は、ぜひご利用ください。 また、GitHub で私にフィードバックを送っていただくことも歓迎です。気に入ったら、星を付けてください。
📖 深入探索相關主題