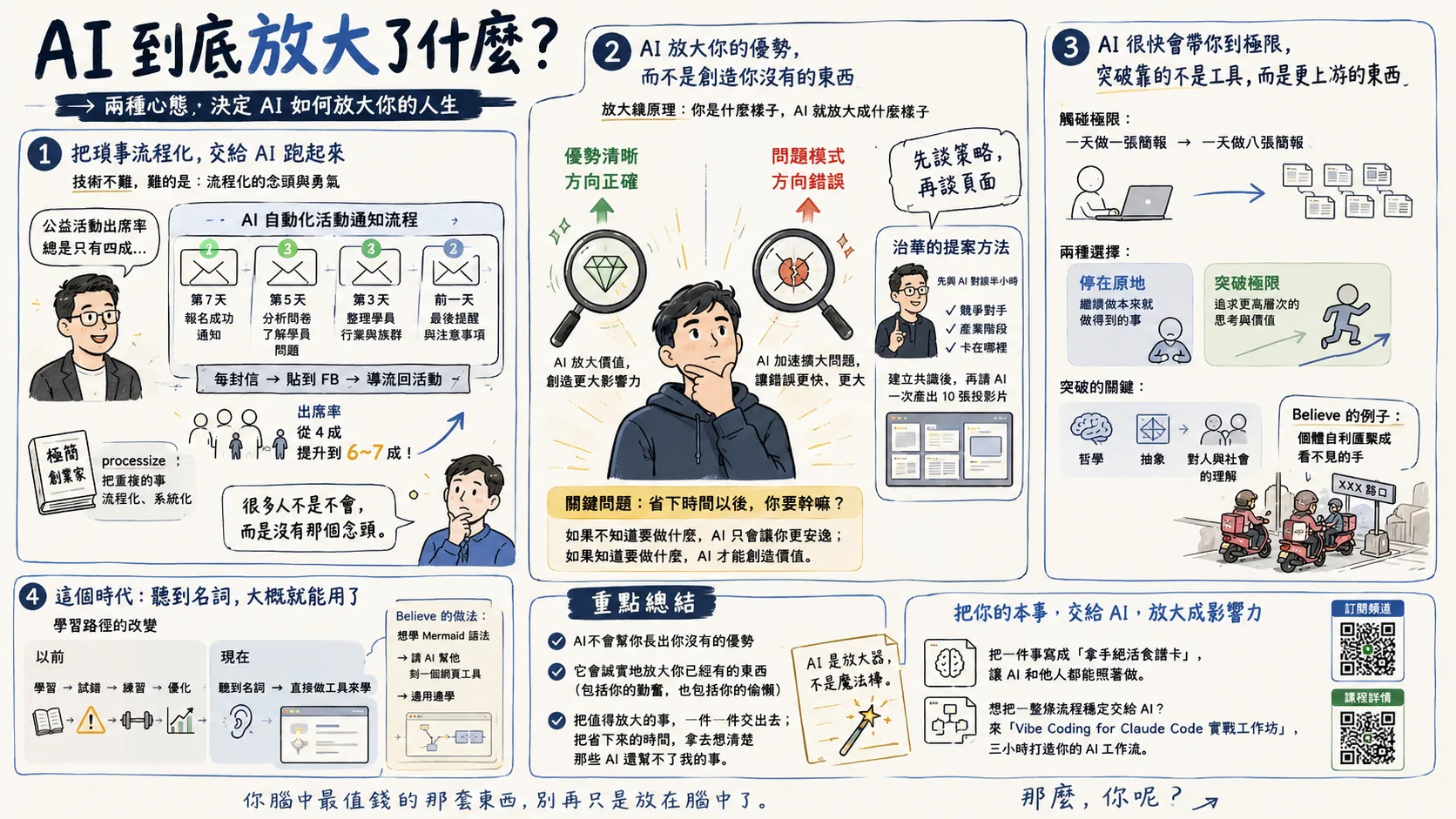
YouTube 逐字稿總是又髒又重複?我用一個早上做了一個乾淨的開源小工具 video-notes
▲ 一個每天都會用到的小工具,常常就藏在你最熟悉的那個麻煩裡。
我常看 YouTube 上的技術演講和訪談,看完想留一份逐字稿,再整理成幾個重點,方便日後寫作或查找。其實怎麼用 AI 工具快速摘要、整理講座內容,我之前也寫過;而這次我想更進一步,從源頭把逐字稿弄乾淨。市面上這類工具不少,但用過一輪後,我發現它們有個共通的毛病:吐出來的逐字稿不是很乾淨。於是我花了一個早上,自己做了一個清爽的版本,取名 video-notes,現在把它開源出來。
這篇文章分兩段:前半是開發過程裡幾個我覺得值得記下來的判斷,後半是給你的使用教學。原始碼在這裡:github.com/iamvista/video-notes。
它做什麼
一言以蔽之,只要給它一個 YouTube 連結或一個本地影片檔,它會產出兩份 Markdown:一份是帶時間戳的完整逐字稿,一份是整理過的重點筆記(含 TL;DR、分主題的要點、可點選跳轉的章節)。
簡單來說,它是一個 Claude Code 的 skill(不會寫程式也沒關係,我之前寫過一篇文組人也能用 Claude Code 的完全自學指南)。比較特別的設計是分工:Python 腳本只負責把逐字稿抓乾淨,重點、摘要、章節這些需要判斷的部分,交給 AI 讀完逐字稿後自己寫。這樣寫出來的筆記讀起來像人做的,而不是再呼叫一次 API 硬湊出來的條列。
開發心得
一、零依賴是一種偏執,但值得
整個工具是由七支 Python 腳本組成,全部只用標準函式庫,沒有任何 pip 套件。需要的只有三個系統工具:yt-dlp、ffmpeg、curl,這些本來就常駐在我的開發機上。
為什麼這麼堅持?因為這種小工具最怕的就是半年後回來想用,結果卡在套件版本衝突、虛擬環境壞掉、某個依賴停止維護。少一層依賴,就少一個未來會壞的地方。連打 Whisper API 我都直接用 curl,而不是裝 openai 套件。這份偏執讓它幾乎不會因為環境變動而失靈。
二、YouTube 自動字幕的滾動重複,是這個工具真正的難點
如果你抓過 YouTube 的自動字幕,會發現它偶爾會發生每個字都重複的現象。原因是自動字幕用的是兩行滾動視窗的格式:上一句的尾巴會跟下一句的開頭疊在一起,一個字會在相鄰的字幕塊裡出現兩三次。直接拼起來,整份逐字稿讀起來就是結巴的鬼打牆。
這是大多數同類工具會搞砸的地方。我處理的方式是針對兩種重疊各寫一招:一種是後一塊字幕完整包含前一塊(成長型),就用比較長的那塊取代;另一種是滑動視窗的部分重疊,我去比對前一塊尾端和後一塊開頭最大的重複片段,只留下真正新增的字。處理完,逐字稿就讀一次到底,不結巴。
 ▲ 把 YouTube 滾動字幕的重複疊字去掉,逐字稿才讀得下去。這段去重邏輯,是這個工具最花心力、也最值得的地方。
▲ 把 YouTube 滾動字幕的重複疊字去掉,逐字稿才讀得下去。這段去重邏輯,是這個工具最花心力、也最值得的地方。
這段邏輯佔了整個專案最多的心力,也是我覺得它比別人乾淨的關鍵。
三、不要機器翻譯的字幕,要原文
一支有自動字幕的 YouTube 影片,背後其實掛著大約一百五十條自動翻譯的字幕軌。很多工具會圖方便,看到你要中文就直接抓機翻中文字幕。但機翻字幕的品質遠低於原始語言的辨識結果。
所以我刻意只抓原文軌:先找人工字幕,再找原始語言的人工字幕,最後才退到原始語言的自動字幕。翻譯這件事,留到 AI 整理摘要的時候再做,那一步的理解力遠勝逐字機翻。寧可拿到一份準確的英文逐字稿,也不要一份歪掉的中文。
四、字幕優先,Whisper 只是後備
能拿到字幕就用字幕,這是最快也最省的路。只有當影片完全沒有可用字幕(例如本地影片檔,或關了字幕的影片),才會走 Whisper:抽出低位元率的單聲道音訊,依檔案大小切成每塊不超過 API 上限的小段,逐段轉錄後再把時間戳接回去。
也因為這樣,OPENAI_API_KEY 是選用的。大多數情況根本用不到,只有真的要轉錄音訊時才需要設。我把這個檢查延後到真正需要的那一刻,而不是一開始就擋你。
五、公開化,是一次把私心拆掉的練習
我自己用的版本,輸出是直接寫進我的 Obsidian 知識庫,路徑和欄位格式都是為我個人工作流寫死的。要開源,就得把這些東西先拆掉。
我把寫死的路徑全換成一個通用的 —out-dir 參數,預設輸出到當前目錄。原本綁定知識庫的那個功能,改寫成文件裡的一段範例,告訴你怎麼把輸出接到你自己的筆記系統。骨幹保持通用,目的地交給使用者決定。這個拆解的過程,其實也讓我重新想清楚哪些是工具本質、哪些只是我的習慣。
使用教學
前置安裝
先裝三個系統工具(以 macOS 為例):
brew install yt-dlp ffmpegPython 只要 3.9 以上,不用 pip install 任何東西。
把 skill 複製到 Claude Code 的 skills 目錄:
git clone https://github.com/iamvista/video-notes ~/.claude/skills/video-notes基本用法
在 Claude Code 裡直接呼叫:
/video-notes https://youtu.be/<影片id>處理本地影片檔,並指定輸出目錄與語言:
/video-notes ./talk.mp4 --out-dir ./notes --lang zh跑完你會拿到兩個檔:一份重點筆記,一份完整逐字稿。YouTube 來源的章節時間戳會是可點選的跳轉連結。
不靠 AI,直接當命令列工具用
如果你只想要乾淨的逐字稿,自己決定後續怎麼整理,可以直接跑底層的 CLI。它會吐一份 transcript.json:
python3 scripts/cli.py "https://youtu.be/<影片id>" --lang zh --out ./out
cat ./out/transcript.jsonJSON 裡有影片資訊(標題、頻道與長度)、逐字稿來源是字幕還是 Whisper、以及每一段的起始秒數和文字。要拿去餵別的流程也很方便。
沒有字幕的影片怎麼辦
如果影片沒有任何可用字幕,工具會自動走 Whisper 轉錄。這時,你需要先設好金鑰:
export OPENAI_API_KEY=sk-...有字幕的影片,完全用不到這一步。
接到你自己的知識庫
—out-dir 就是給你客製的接縫。把它指向你的筆記庫收件匣,再依照 SKILL.md 第五步的說明,調整筆記的 frontmatter 欄位成你習慣的格式,就能把每支影片的筆記自動歸檔進你的系統。逐字稿管線保持通用,要長成什麼樣子由你決定。
一點反思
這個工具從想法到開源,前後大概一個早上。對我來說,它印證了一件事:當你清楚知道自己要什麼、也願意把細節做對(像那段去重邏輯),vibe coding 不只是快,而是能做出比現成工具更貼合需求的東西。這也呼應我先前談過的,活用 AI 的起點不是挑工具,而是拆解工作流程。
video-notes 就是一個早上 vibe coding 出來的小工具。 如果你也想學會用日常語言描述、讓 AI 把點子當天做成一個有網址的上線作品,歡迎來我開的 Vibe Coding 實戰工作坊:零基礎、不需要任何工程背景,三小時帶一個真正屬於你的作品回家。

老實說這個工具的架構並不大,但我每天都會用到。當工具的門檻被 AI 抹平,真正值錢的會是你的判斷與品味:你有沒有看出那份逐字稿其實很髒、又願不願意花一個早上把它弄乾淨。如果你也常被影片逐字稿的雜訊困擾,歡迎拿去用,也歡迎到 GitHub 上給我回饋;如果喜歡的話,請幫我按一顆星。
📖 深入探索相關主題